Last updated: 5th August 2018
Welcome to my comprehensive collection of tips on running Node.JS in production. It aims to summarize most of the knowledge gathered to date from the highest ranked blog posts.
Don’t miss out: nearby each best practice a “GIST Popup” icon appears ![]() , clicking on it will show further explanation, quotes and code examples
, clicking on it will show further explanation, quotes and code examples
Written by Yoni Goldberg – An independent Node.JS consultant who provide Node consulting and training. See also my GitHub with over 70+ best practices
1. Monitoring!TL;DR: Monitoring is a game of finding out issues before our customers do – obviously this should be assigned unprecedented importance. The market is overwhelmed with offers thus consider starting with defining the basic metrics you must follow (my suggestions inside), then go over additional fancy features and choose the solution that tick all boxes. Click ‘The Gist’ below for overview of solutions Otherwise: Failure === disappointed customers. Simple.
|
|
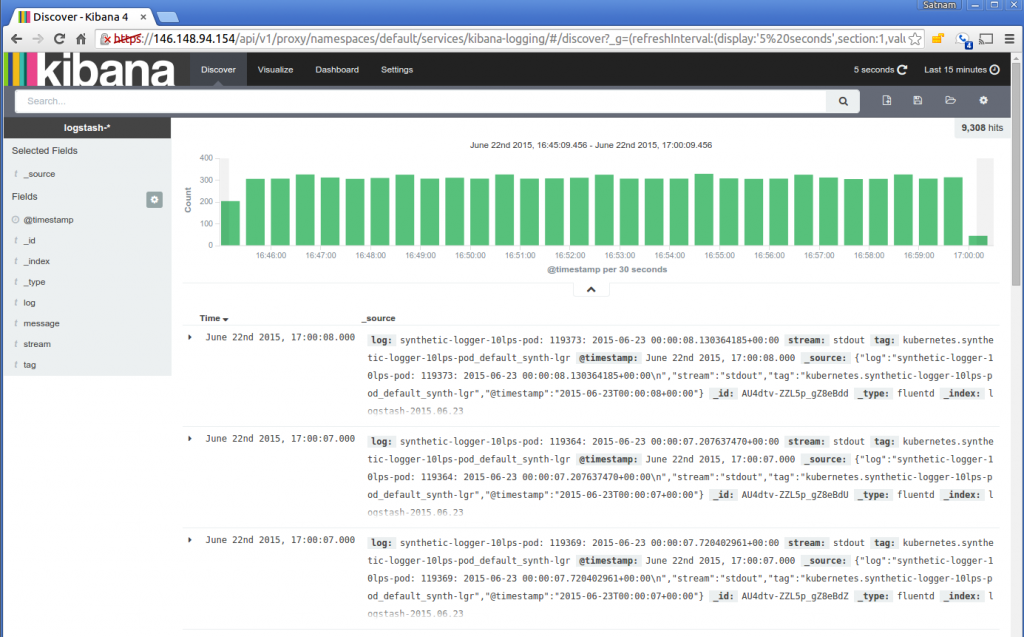
2. Increase transparency using smart loggingTL;DR: Logs can be a dumb warehouse of debug statements or the enabler of a beautiful dashboard that tells the story of your app. Plan your logging platform from day 1: how logs are collected, stored and analyzed to ensure that the desired information (e.g. error rate, following an entire transaction through services and servers, etc) can really be extracted Otherwise: You end-up with a blackbox that is hard to reason about, then you start re-writing all logging statements to add additional information
|
|
3. Delegate anything possible (e.g. gzip, SSL) to a reverse proxyTL;DR: Node is awfully bad at doing CPU intensive tasks like gzipping, SSL termination, etc. Instead, use a ‘real’ middleware services like nginx, HAproxy or cloud vendor services Otherwise: Your poor single thread will keep busy doing networking tasks instead of dealing with your application core and performance will degrade accordingly
|
|
4. Lock dependenciesTL;DR: Your code must be identical across all environments but amazingly NPM lets dependencies drift across environments be default – when you install packages at various environments it tries to fetch packages’ latest patch version. Overcome this by using NPM config files , .npmrc, that tell each environment to save the exact (not the latest) version of each package. Alternatively, for finer grain control use NPM” shrinkwrap”. *Update: as of NPM5 , dependencies are locked by default. The new package manager in town, Yarn, also got us covered by defaultOtherwise: QA will thoroughly test the code and approve a version that will behave differently at production. Even worse, different servers at the same production cluster might run different code
|
|
|
|
|
5. Guard process uptime using the right toolTL;DR: The process must go on and get restarted upon failures. For simple scenario, ‘restarter’ tools like PM2 might be enough but in today ‘dockerized’ world – a cluster management tools should be considered as well Otherwise: Running dozens of instances without clear strategy and too many tools together (cluster management, docker, PM2) might lead to a devops chaos
|
|
6. Ensure error management best practices are metTL;DR: Error management must be the most time-consuming and painful task in keeping Node.JS environments stable. This is happening mostly due to the ‘one thread’ model and the lack of proper strategy for error paths in asynchronous flows. No shortcuts here, you must fully understand and tame the error management beast. My list of error handling best practices might get you there quicker Otherwise: Crazy stuff will go on such as process crashing only because a user passed-in an invalid JSON, errors disappear without a trace and stack-trace information revealed to the end-user
|
|
7. Utilize all CPU coresTL;DR: At its basic form, a Node app runs over a single CPU core while as all other are left idle. It’s your duty to replicate the Node process and utilize all CPUs – For small-medium apps you may use Node Cluster or PM2. For a larger app consider replicating the process using some Docker cluster (e.g. K8S, ECS) or deployment scripts that are based on Linux init system (e.g. systemd) Otherwise: Your app will likely utilize only 25% of its available resources(!) or even less. Note that a typical server has 4 CPU cores or more, naive deployment of Node.JS utilizes only 1 (even using PaaS services like AWS beanstalk!)
|
|
8. Create a ‘maintenance endpoint’TL;DR: Expose a set of system-related information, like memory usage and REPL, etc in a secured API. Although it’s highly recommended to rely on standard and battle-tests tools, some valuable information and operations are easier done using code Otherwise: You’ll find that you’re performing many “diagnostic deploys” – shipping code to production only to extract some information for diagnostic purposes
|
|
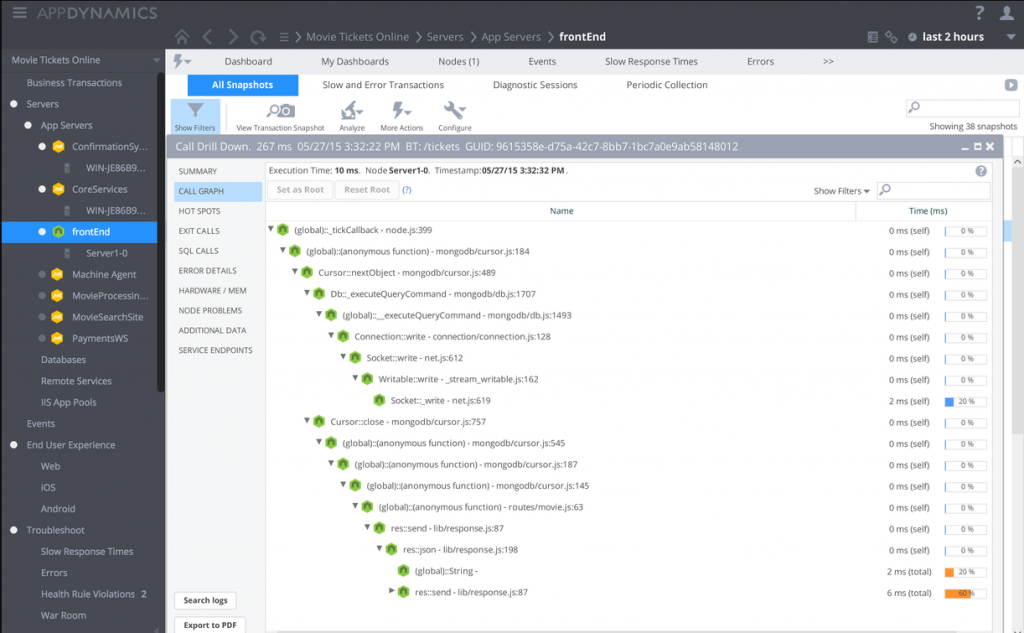
9. Discover errors and downtime using APM productsTL;DR: Monitoring and performance products (a.k.a APM) proactively gauge codebase and API so they can auto-magically go beyond traditional monitoring and measure the overall user-experience across services and tiers. For example, some APM products can highlight a transaction that loads too slow on the end-users side while suggesting the root cause Otherwise: You might spend great effort on measuring API performance and downtimes, probably you’ll never be aware which is your slowest code parts under real world scenario and how these affects the UX
|
|
10. Make your code production-readyTL;DR: Code with the end in mind, plan for production from day 1. This sounds a bit vague so I’ve compiled inside (click Gist below) few development tips that are closely related to production maintenance Otherwise: A world champion IT/devops guy won’t save a system that is badly written
|
|
11. Tick the obvious security boxesTL;DR: Node embodies some unique security challenges, in this bullet I’ve grouped the straightforward security measures. Goes without saying that a “Secured” system requires a much more extensive security analysis Otherwise: What is worth than a security leak that is covered in press? a no-brainer security issue that you just forgot to address
|
|
Love this? read my ‘Error Handling Best Practices’ guide |
|
12. Measure and guard the memory usageTL;DR: Node.js has controversial relationships with memory: the v8 engine has soft limits on memory usage (1.4GB) and there are known paths to leaks memory in Node’s code – thus watching Node’s process memory is a must. In small apps you may gauge memory periodically using shell commands but in medium-large app consider baking your memory watch into a robust monitoring system Otherwise: Your process memory might leak a hundred megabytes a day like happened in Wallmart
|
|
13. Get your frontend assets out of NodeTL;DR: Serve frontend content using dedicated middleware (nginx, S3, CDN) because Node performance really get hurts when dealing with many static files due to its single threaded model Otherwise: Your single Node thread will keep busy streaming hundreds of html/images/angular/react files instead of allocating all its resources for the task it was born for – serving dynamic content
|
|
14. Be stateless, kill your Servers almost every dayTL;DR: Store any type of data (e.g. users session, cache, uploaded files) within external data stores. Consider ‘killing’ your servers periodically or use ‘serverless’ platform (e.g. AWS Lambda) that explicitly enforces a stateless behavior Otherwise: Failure at a given server will result in application downtime instead of a just killing a faulty machine. Moreover, scaling-out elasticity will get more challenging due to the reliance on a specific server
|
|
15. Use tools that automatically detect vulnerabilitiesTL;DR: Even the most reputable dependencies such as Express have known vulnerabilities from time to time that put a system at risk. This can get easily tamed using community and commercial tools that constantly check for vulnerabilities and warn (locally or at GitHub), some can even patch them immediately Otherwise: Keeping your code clean from vulnerabilities without dedicated tools will require to constantly follow online publications about new threats. Quite tedious
|
|
16. Assign ‘TransactionId’ to each log statementTL;DR: Assign the same identifier, transaction-id: {some value}, to each log entry within a single request. Then when inspecting errors in logs, easily conclude what happened before and after. Unfortunately, this is not easy to achieve in Node due its async nature, see code examples inside Otherwise: Looking at a production error log without the context – what happened before – makes it much harder and slower to reason about the issue
|
|
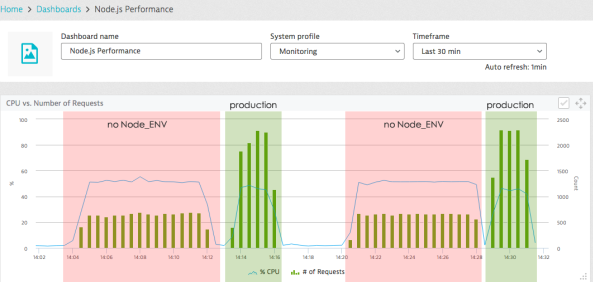
17. Set NODE_ENV=productionTL;DR: Set the environment variable NODE_ENV to ‘production’ or ‘development’ to flag whether production optimizations should get activated – many NPM packages determining the current environment and optimize their code for production Otherwise: Omitting this simple property might greatly degrade performance. For example, when using Express for server side rendering omitting NODE_ENV makes the slower by a factor of three!
|
|
18. Design automated, atomic and zero-downtime deploymentsTL;DR: Researches show that teams who perform many deployments – lowers the probability of severe production issues. Fast and automated deployments that don’t require risky manual steps and service downtime significantly improves the deployment process. You should probably achieve that using Docker combined with CI tools as they became the industry standard for streamlined deployment Otherwise: Long deployments -> production down time & human-related error -> team unconfident and in making deployment -> less deployments and features Generic topic, read further information on the web. This topic is not related directly to Node.JS. |
|
19. Bump your NPM version in each deploymentTL;DR: Anytime a new version is released, increase the package.json version attribute so that it will become clear in production which version is deployed. All the more so in MicroService environment where different servers might hold different versions. The command “npm version” can achieve that for you automatically Otherwise: Frequently developers try to hunt a production bug within a distributed system (i.e.multiple versions of multiple services) only to realize that the presumed version is not deployed where they look at |
|
20. Use an LTS release of NodejsTL;DR: Ensure you are using an LTS version of Node.js to receive critical bug fixes, security updates and performance improvements Otherwise: Newly discovered bugs or vulnerabilities could be used to exploit an application running in production, and your application may become unsupported by various modules and harder to maintain |
|
21. Check your monitoring against real chaos (using a monkey)TL;DR: Life tells us that unpredicted things will happen in production. To name of a few, servers will get killed, SSL certificate validity may get revoked, the event loop tends to get blocked, DNS records may change and it goes on. These sound like rare conditions, but they do happen and usually leaves a huge impact like a storm. There’s no way to truly mitigate this risk without simulating these chaotic conditions and verifying that the application can survive or at least report their occurrence. Netflix chaos-monkey is the most famous tool for chaos generation. My Nodejs chaos monkey is focused on node and process related chaos Otherwise: No escape here, Murphy’s law will hit your production without mercy |
|
22. Stay tuned, more are coming soonTL;DR: I’m about to write here soon about other production best practices like post-mortem debugging, tuning the libuv thread pool, creating production smoke tests and more. Want to stay updated? Follow my Twitter or Facebook pages |
-
Icaro Tavares
-
Yoni Goldberg
-
-
German Torvert
-
Yoni Goldberg
-
-
Mike Robinson
-
Yoni Goldberg
-
-
Andrzej
-
Yoni Goldberg
-
Mike Datsko
-
Yoni Goldberg
-
Mike Datsko
-
Yoni Goldberg
-
Mike Datsko
-
Yoni Goldberg
-
Mike Datsko
-
-
-
-
-
Leonardo Rodriguez
-
Yoni Goldberg
-
-
dman777
-
Yoni Goldberg
-
-
John Best
-
Yoni Goldberg
-
-
cztomsik
-
Yoni Goldberg
-
-
Stefan Thies
-
Yoni Goldberg
-
Stefan Thies
-
-
-
Rakibul Haq
-
Muhammad Rifa’i
-
Raj Peddisetty
-
Yoni Goldberg
-